Day 61 :Spread Simulation: Randomizing the Gap Between Bid and Ask

Before You Start
Make sure you have your Alpaca paper trading credentials ready. Export them as environment variables now so the demo and execution scripts can pick them up automatically:
export ALPACA_API_KEY="your_paper_key"
export ALPACA_SECRET_KEY="your_paper_secret"
export ALPACA_BASE_URL="https://paper-api.alpaca.markets"
If you skip this, the executor will fall back to simulation mode automatically — you will still see everything working, just without real Alpaca order IDs in the log.
Confirm your Python version while you are here:
python --version
# Must print 3.11.x or higher
Part 1 — The Problem: Why Every Beginner Gets This Wrong
Every junior quant makes this mistake on their first backtester:
# The graveyard of careers
MID_PRICE = 150.00
SPREAD = 0.01 # "It's just one cent, it barely matters"
bid = MID_PRICE - SPREAD / 2
ask = MID_PRICE + SPREAD / 2
This code will pass your unit tests, look perfectly reasonable in your backtest, and then silently destroy your live performance. Here is why: a fixed spread assumes markets are always liquid, always calm, and always willing to transact at the prices you expect. Real markets are never all three of those things at once.
The AAPL spread at 09:30:01 EST is not the same as at 14:47:33 EST. The SPY spread during a VIX spike to 35 is not the same as during a quiet drift day. If your model was trained on post-2022 low-volatility data and uses a hardcoded 1-cent spread, you are not modeling costs — you are modeling your hope about costs.
The real-world consequence looks like this: your Sharpe ratio in backtest is 1.8. In live trading, after realistic spread friction during just three volatility events per quarter, it collapses to 0.6. Not because your alpha decayed. Because you did not model the cost of being wrong about liquidity.
Part 2 — Three Ways Naive Implementations Break
2.1 Uniform Spread Across All Market Conditions
Spreads are heteroskedastic — their variance changes dramatically with market conditions. During normal hours the SPY spread is around 1 basis point. During a flash crash it can gap to 50+ bps momentarily. A model that ignores this:
Overestimates profitability in high-volatility regimes
Underestimates fill certainty during calm markets (you could actually get better fills than you modeled)
Produces a P&L surface that is optimistic exactly when you can least afford it to be
2.2 Float Arithmetic Accumulation
# This is a trap at scale
mid = 0.1 + 0.2 # --> 0.30000000000000004
half_spread = 0.005
bid = mid - half_spread # compounding error in P&L over 1M fills
Over 1,000,000 simulated ticks, floating-point drift in the spread calculation creates a P&L discrepancy that looks indistinguishable from real alpha. You will think your strategy has an edge. It has arithmetic noise.
2.3 Blocking Recalculation in a Hot Path
A naive implementation recalculates the spread for every tick with a Python for loop. At 10,000 ticks per second, a 0.5 microsecond overhead per iteration compounds to 5ms of pure spin per second — enough latency to cause slippage on every fast-moving signal.
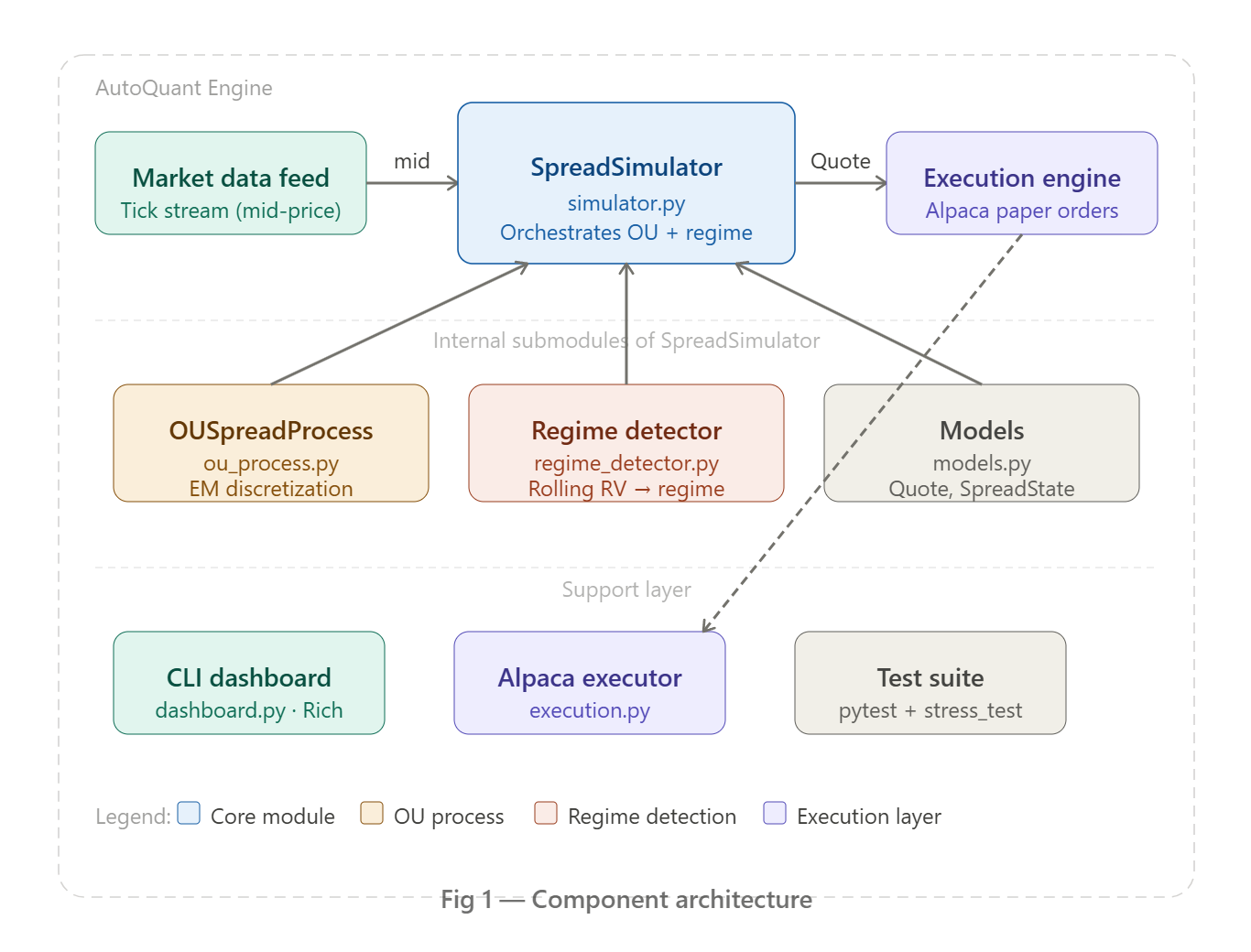
Part 3 — The Architecture: How We Actually Do It